Smart Kubernetes Scheduling: Balancing Cost Efficiency and Resilience


Introduction
Kubernetes pod scheduling is more than a background process—it is a key decision‑making layer that determines where your workloads run, how much they cost, and how resilient they are under pressure.
Cloud-native teams constantly face the same challenge:
How can we minimize cloud spend while keeping applications highly available?
This post explores that balance. You will learn how Kubernetes makes scheduling decisions, what trade‑offs you need to consider, and practical strategies to achieve both cost efficiency and resilience.
How Kubernetes Scheduling Works
When you deploy a pod, Kubernetes does not place it randomly. The scheduler evaluates the cluster through three main phases:
- Filtering: Nodes that don’t meet resource requests, affinity rules, or taint tolerations are excluded.
- Scoring: Each eligible node is scored based on priorities such as available CPU/memory, topology spread, and custom rules.
- Binding: The scheduler assigns the pod to the highest‑scoring node.
Understanding this workflow is critical when tuning your cluster for cost and resilience.
The Core Trade‑Off: Cost vs. Resilience
- Cost Efficiency: Packing workloads onto fewer nodes or using cheaper node types (like Spot or Preemptible instances) lowers your bill.
- Resilience: Spreading pods across zones, maintaining replicas, and avoiding over‑commitment ensures uptime even during failures.
Over‑optimizing for one often hurts the other. For example, aggressively consolidating pods can lead to resource contention or evictions during node failures. On the other hand, over‑spreading workloads can leave expensive nodes underutilized.
Key Factors Influencing Scheduling Decisions
- Resource Requests and Limits: Proper sizing prevents waste and avoids throttling.
- Affinity and Anti‑Affinity Rules: Decide whether pods should run together or be kept apart.
- Topology Spread Constraints: Force pods to distribute across zones, racks, or regions.
- Taints and Tolerations: Isolate critical workloads or keep test workloads on cheaper nodes.
- Pod Priority and Preemption: Ensure important pods get scheduled first during resource crunches.
Strategies for Cost‑Efficient Scheduling
✅ Right‑Size Everything: Regularly audit CPU and memory requests to avoid over‑provisioning.
✅ Use Mixed Node Pools: Run critical workloads on stable nodes and use Spot instances for less critical, stateless workloads.
✅ Autoscale Intelligently: Combine Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA) to scale dynamically without over‑allocating.
✅ Descheduler Tools: Use Kubernetes descheduler or third‑party platforms to evict and reschedule pods onto more cost‑effective nodes.
Strategies for Resilient Scheduling
✅ Topology Spread Constraints: Spread pods evenly across zones to avoid single points of failure.
✅ Anti‑Affinity Rules: Prevent critical replicas from co‑locating on the same node.
✅ Pod Disruption Budgets (PDBs): Limit how many pods can be down during maintenance or autoscaling.
✅ Health Probes: Readiness and liveness probes guide the scheduler to avoid unhealthy nodes.
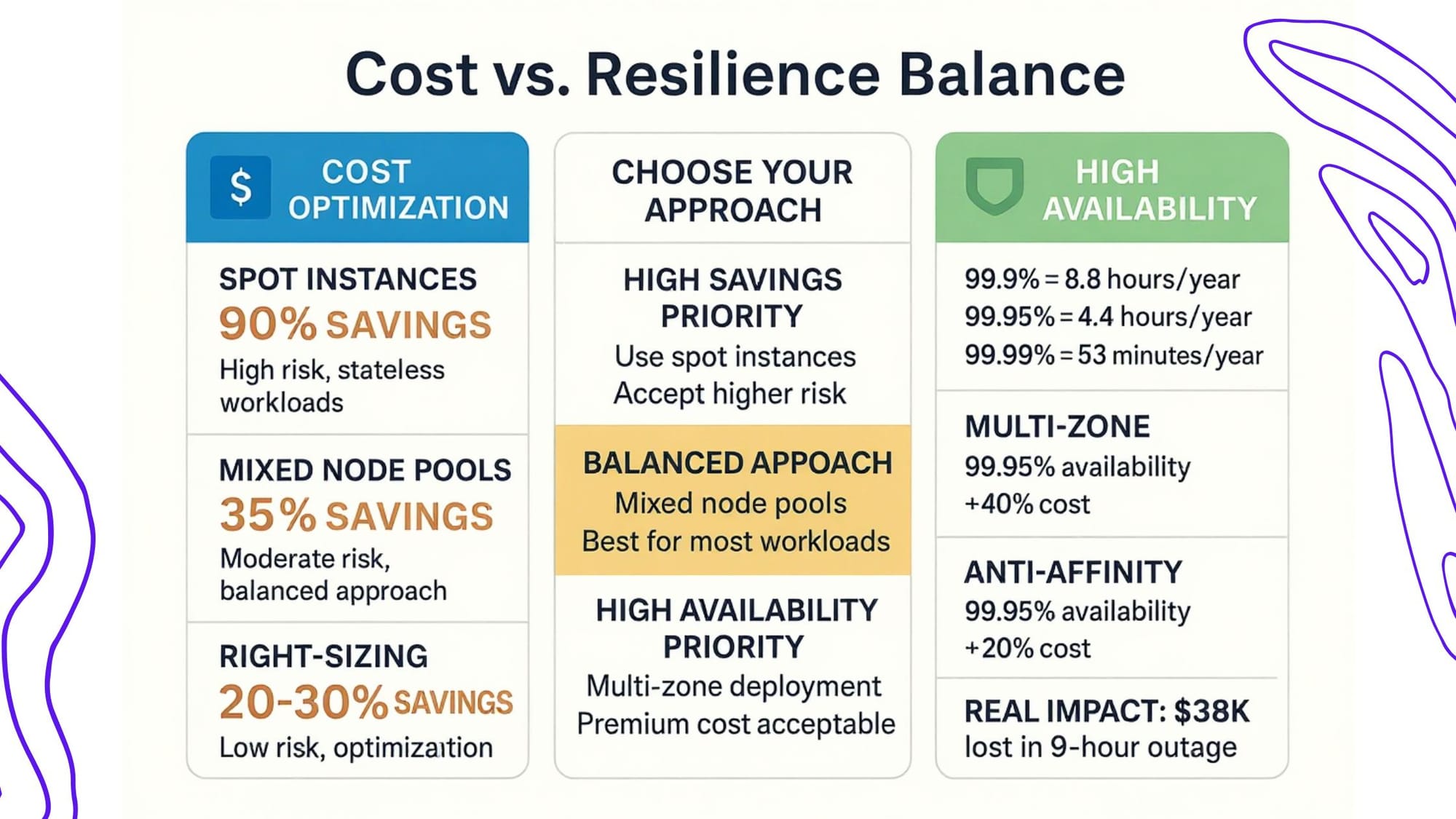
Bridging the Gap: Cost and Resilience Together
A balanced setup uses a combination of hard constraints (for critical workloads) and soft preferences (for less critical ones).
Example:
- Set strict anti‑affinity for your primary database pods.
- Allow background processing pods to prefer cheaper nodes, but not require them.
This hybrid approach allows you to save costs while keeping essential services protected.
Advanced Tools and Automation
Manually tuning these settings is possible, but large clusters benefit from automation:
- Kubernetes Scheduler Plugins: Extend default behavior with custom scoring rules.
- Descheduler & Autoscaler: Continuously adjust workloads based on real‑time data.
- Third‑Party Optimization Platforms (like Stackbooster): Automated rightsizing, cost reporting, and live rescheduling can help achieve both savings and reliability.
Real‑World Use Case
A SaaS company running a multi‑tenant service on GKE used a mixed node pool strategy:
- Critical API pods ran on standard nodes across three zones.
- Batch processing pods used Spot nodes with lower priority.
Result: 35% cloud cost reduction while maintaining a 99.95% availability SLA.
Best Practices Checklist
✔️ Audit resource requests/limits monthly.
✔️ Apply topology spread and anti‑affinity for critical services.
✔️ Mix stable and Spot nodes by workload importance.
✔️ Monitor cost metrics continuously.
✔️ Automate where possible to reduce human error.
Final Thoughts
Kubernetes scheduling is a lever you can actively tune - not just a background task. By combining cost‑efficient practices with resilient design principles, you can achieve a cluster that is both affordable and reliable.
Next step: use Stackbooster to experiment safely in a staging cluster. With Stackbooster’s automation and real‑time insights, you can fine‑tune resource requests, test affinity rules, and instantly see the impact on both cost and uptime. Over time, these data‑driven adjustments compound into significant savings and a more resilient Kubernetes environment.
Frequently Asked Questions
Q: What happens if affinity and topology constraints conflict?
The scheduler attempts to satisfy both. If impossible, the pod may remain pending until constraints are relaxed or capacity is added.
Q: Can I safely use Spot nodes for stateful workloads?
It’s not recommended. Stateful sets need stable infrastructure; use Spot nodes only for stateless or easily replaceable workloads.
Q: How do Pod Disruption Budgets affect scheduling?
PDBs limit voluntary evictions. They ensure that a minimum number of pods remain available during node upgrades or autoscaler actions.



