Cluster Defragmentation #
Cluster Defragmentation helps reduce infrastructure costs and improve efficiency by reorganizing workloads across Kubernetes nodes.
This process replaces fragmented and inefficient nodes with optimized ones, ensuring better resource utilization and lower hourly costs — without compromising availability.
Over time, clusters naturally become fragmented — a normal byproduct of daily operations such as scaling, uneven pod distribution, node taints, or affinity rules.
Additionally, cloud provider pricing can shift, making some instance types less cost-effective than when initially provisioned.
Defragmentation helps by:
- Consolidating workloads onto fewer, better-utilized nodes
- Replacing expensive or poorly matched nodes with cost-effective alternatives
- Adapting to pricing changes to maintain optimal cost/performance balance
- Freeing up capacity for future workloads, reducing unnecessary autoscaling
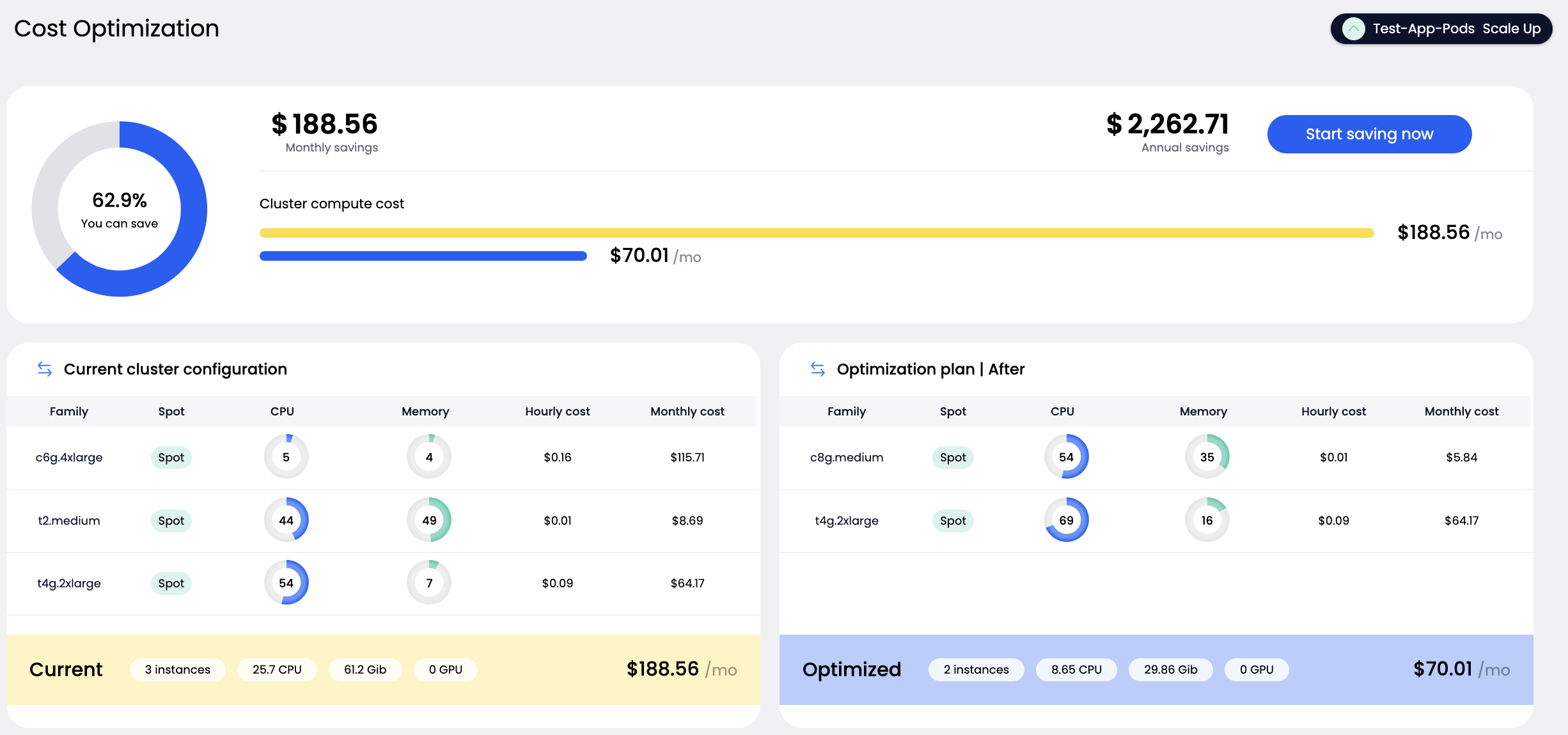
Defragmentation is initiated manually. Before any changes are made, you receive a detailed plan preview, including cost savings and a full before/after topology of your cluster.
How It Works #
When you initiate a defragmentation roll, the system evaluates your current node and pod placement and proposes an optimized configuration. This includes:
- Estimated hourly savings
- Overview of nodes planned for removal and replacement, with detailed configuration of newly proposed nodes
- Per-node breakdowns of utilization, instance type, and pricing
- A summary view comparing current vs. optimized state
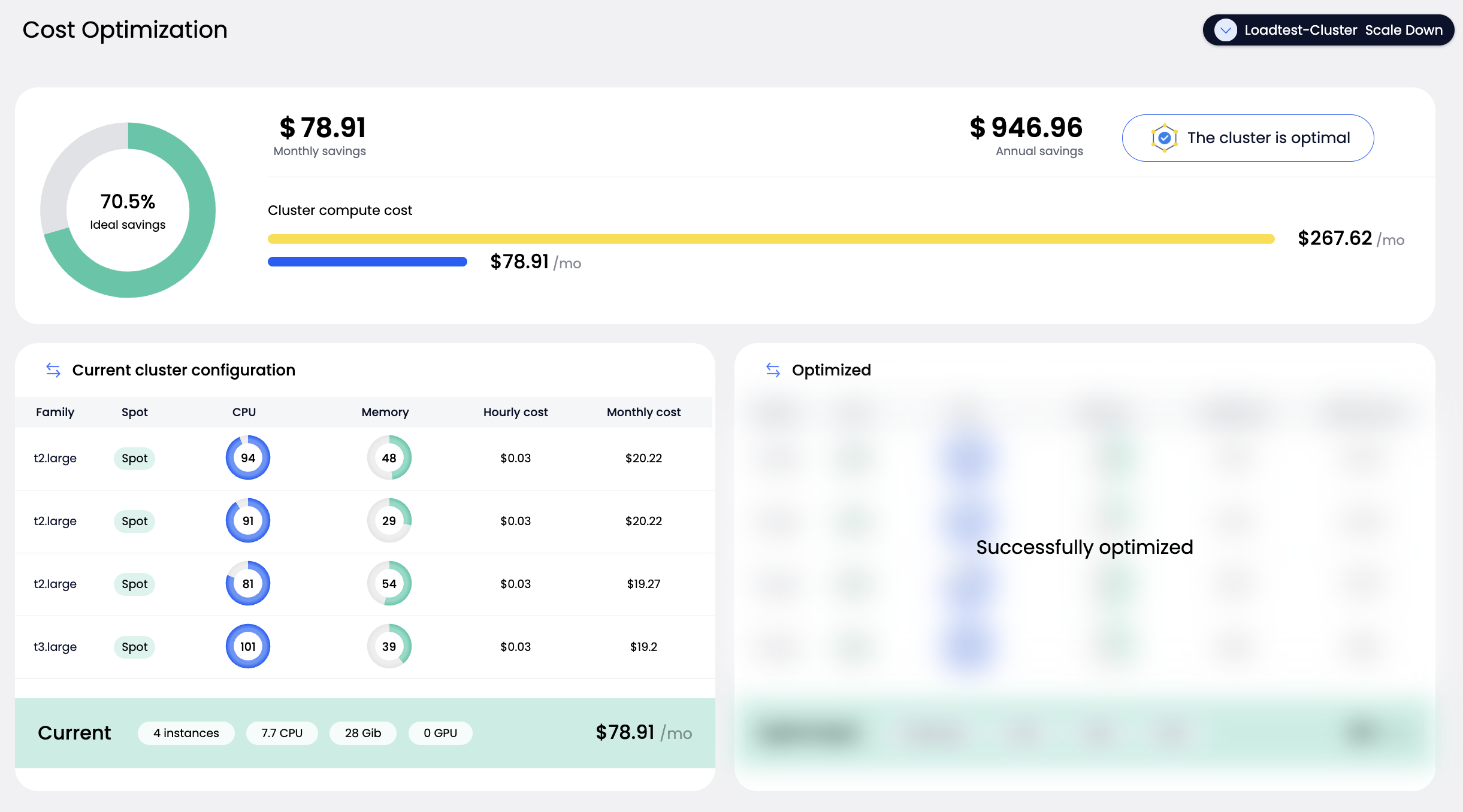
If the analysis shows that your cluster is already cost-efficient, you’ll see a message confirming that no action is needed.
If a roll is started, nodes are replaced in safe, controlled batches. Each new node is verified as Ready, and pods are confirmed to be running before proceeding to drain the corresponding old nodes. This continues until all planned replacements are complete or skipped if unnecessary.
Safety and Reliability #
To ensure your workloads remain uninterrupted, defragmentation is performed with strict safety measures:
- Nodes are only replaced when their workloads can be safely rescheduled.
- Pods protected by Pod Disruption Budgets (PDBs), using ephemeral local storage, or not managed by a controller (e.g. standalone pods) are excluded from replacement.
- Nodes are rolled out in controlled batches, and each new node must pass readiness checks before its corresponding old node is drained.
- If a node fails to provision (e.g. due to lack of capacity), it is skipped and logged without blocking the process.
- Draining respects pod eviction policies and timeouts, allowing for graceful transitions.
These safeguards maintain service stability while enabling cost-efficient optimization.
Launching a Defragmentation Roll #
To initiate the defragmentation process, go to the Defragmentation tab in your cluster view.
If the cluster is eligible, you will see:
- Projected savings (monthly and annual)
- Current node configuration: showing instance types, resource utilization, and costs
- Optimized plan: a preview of the more cost-efficient configuration
To begin the operation:
- Review the optimization plan and projected benefits
- Click the Start saving now button
Once started, the UI will display real-time progress including batch execution status and node transitions.
If the system detects that your cluster is already in an optimal state, it will display a clear message indicating no action is required.
Typical Performance #
| Nodes replaced | Batches | Expected duration* |
|---|---|---|
| 5 | 2 | ~10 min |
| 50 | 4 | ~25 min |
| 200 | 8 | ~55 min |
* Actual timing may vary based on workload readiness, provisioning delays from the cloud provider, and the time needed to gracefully drain workloads from old nodes as defined by your eviction policies and timeouts.